K Mean Clustering
What's K Mean Clustering ?
it's an unsupervised learning algorithim where we use features to group data rows into clusters,
we will discover possible labels for clusters without having y hat to compare to .
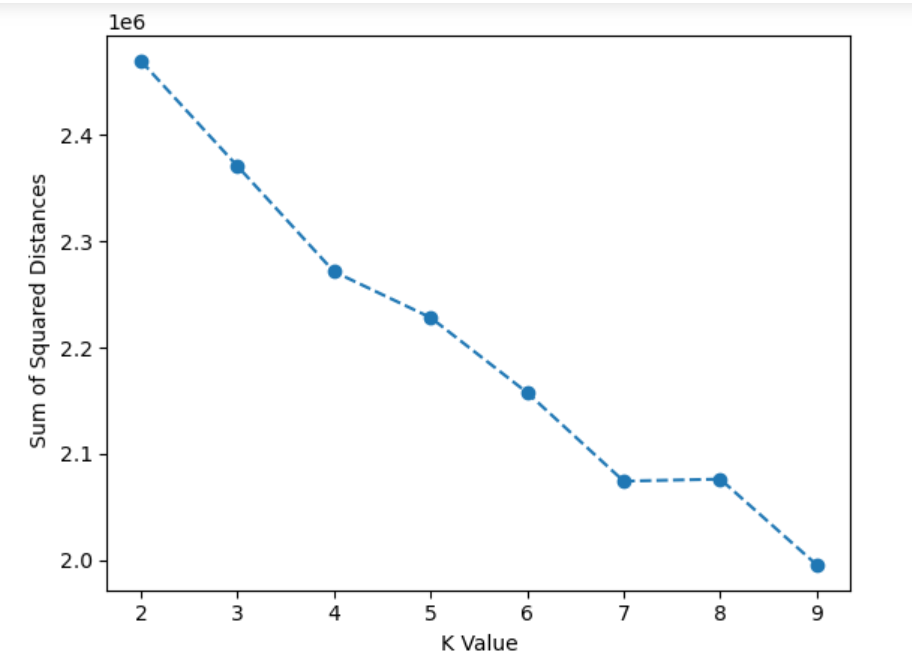
Diffrent methods can be used to decide the number of clusters , but we will use the elbow method .
K Mean Clustering Rules
1- Each point must belong to a cluster .
2- Each point must belong to a single cluster .
K Mean Clustering Steps
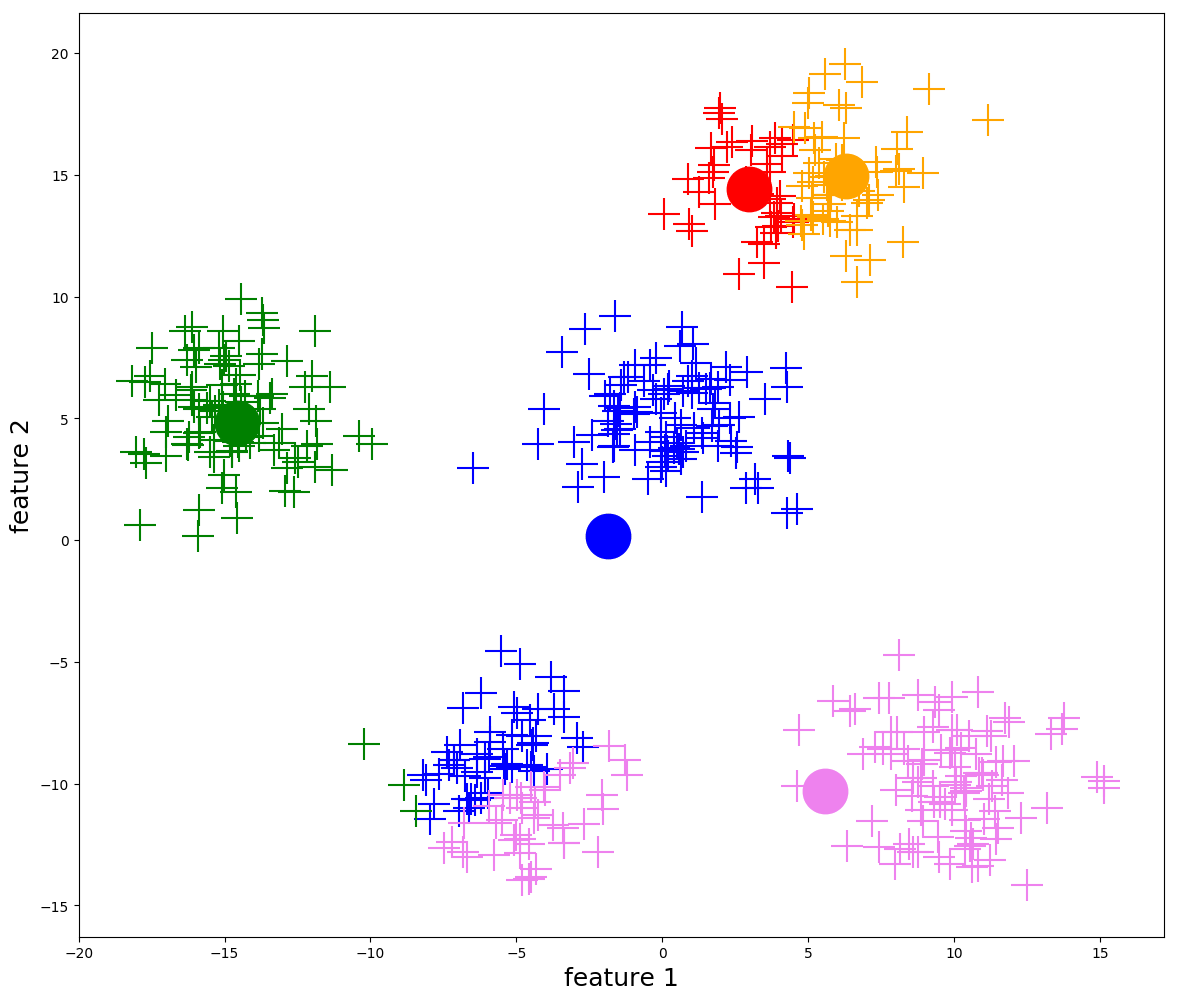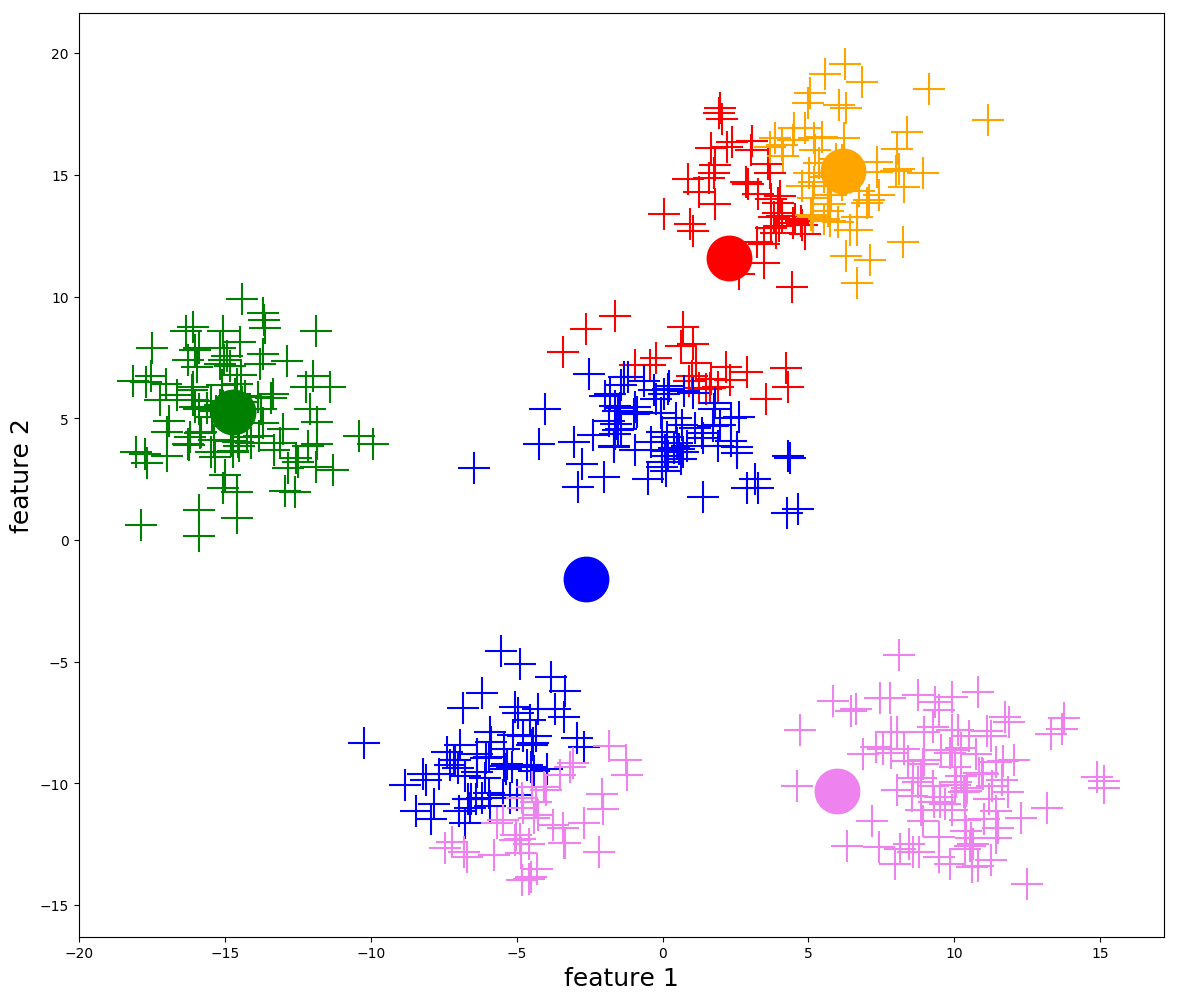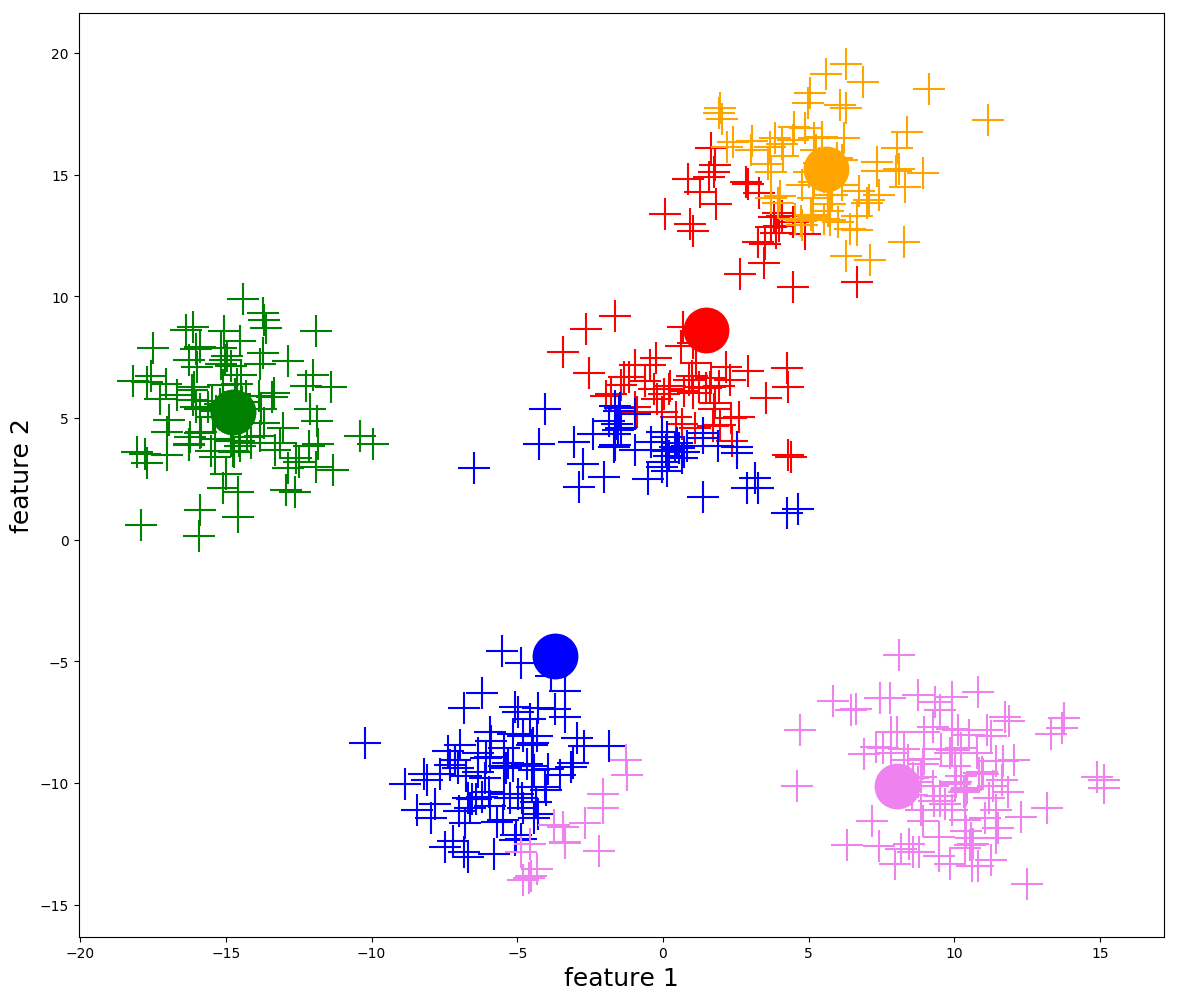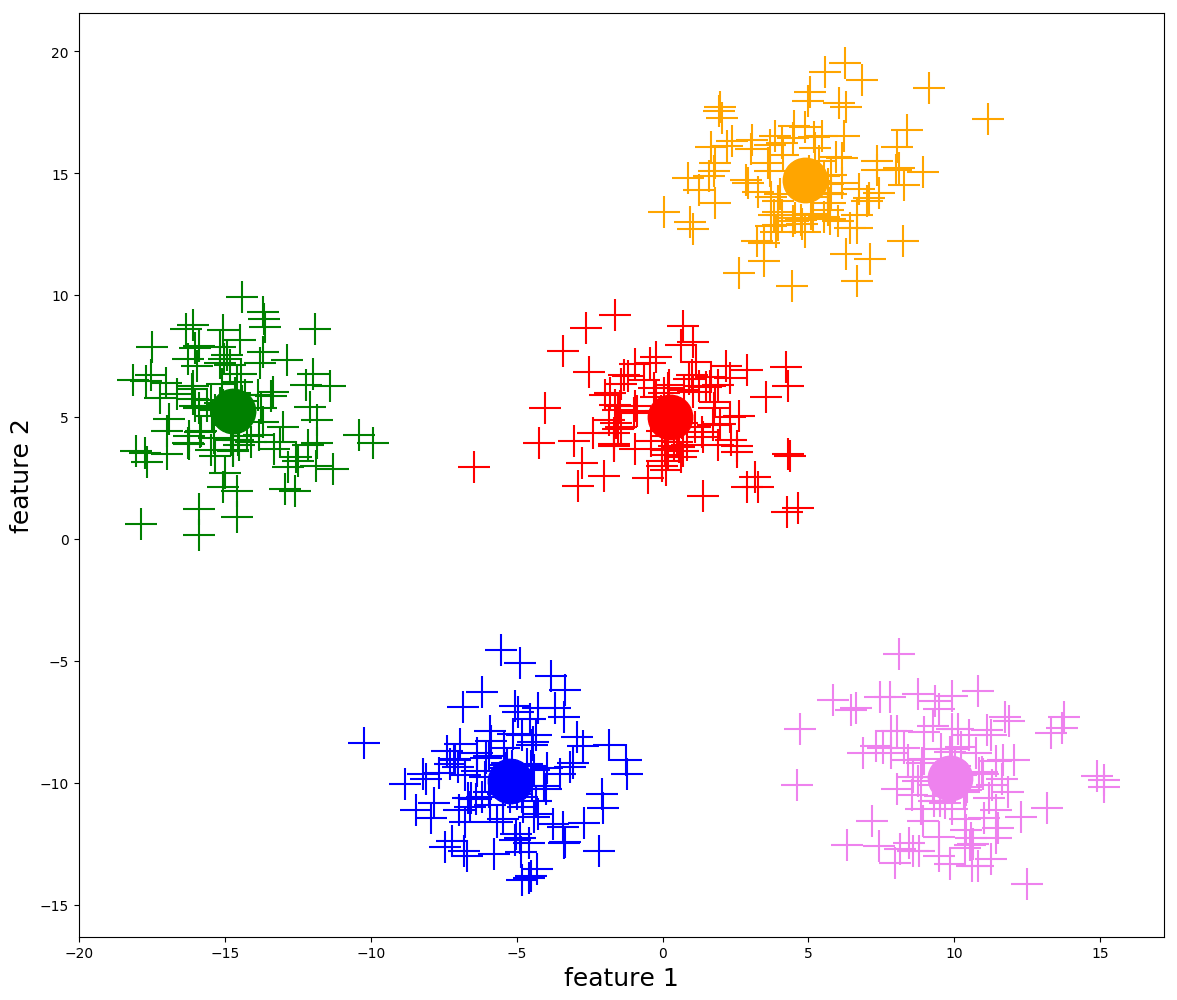
1- Choose K value
2- Randomly select k distincit data points
3- we will treat the selected points as cluster points in which data point closest
to would be classified as them .
4- Calculate mean vector value for each cluster & assign it as the cluster center .
5- iterate to all data points , what cluster cenetrs these points
are closest to ?
some points may be reassigned .
6- repeat from step 4
Elbow Method